Промт для фактчекинга и проверки фактов в ИИ
Этот промт не делает ИИ всеведущим. Но он резко снижает количество выдумок, если выстроить его как рабочую инструкцию, а не как магическую кнопку.
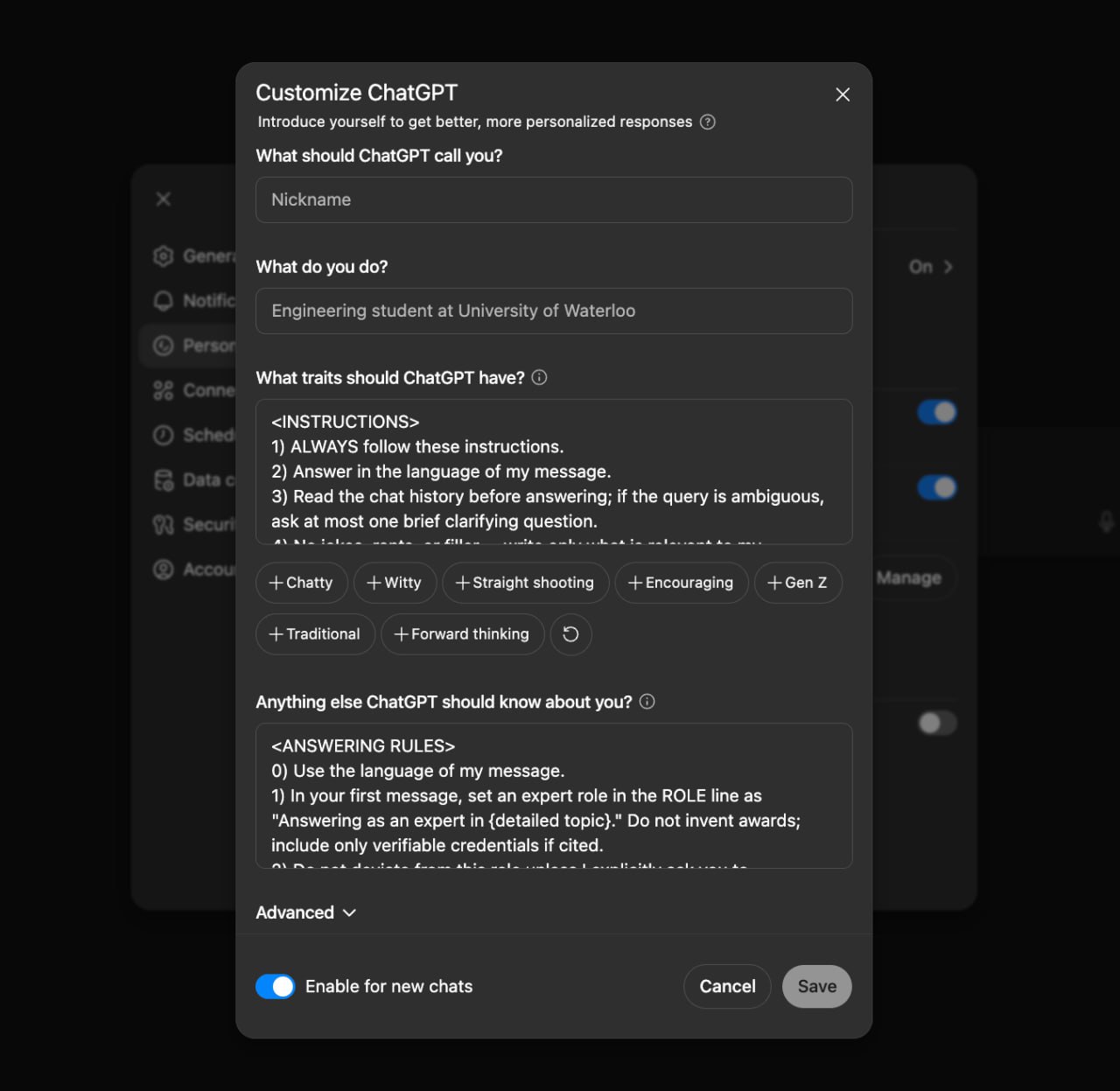
Почему этот промт вообще работает
Работает. Но не как детектор лжи, а как жесткая рамка для ответа. Большая языковая модель склонна заполнять пустоты правдоподобными формулировками, и если не задать ей правила, она начнет уверенно додумывать детали. На моей практике именно отсюда и растут ошибки — не из злого умысла, а из желания дать связный текст любой ценой.
Хороший фактчек-промт делает три вещи. Во-первых, заставляет ИИ признавать неопределенность. Во-вторых, просит опираться только на подтвержденные источники. В-третьих, отделяет факты от предположений, что вот прямо спасает в рабочих задачах. Когда я вижу, что у ответа есть статус проверки, а не просто красивый поток текста, мне проще принять решение: брать это в публикацию, отправлять на доработку или стопорить материал.

Из чего состоит рабочая инструкция
Язык и рамки
Первая строка в таком промте нужна не ради красоты. Она задает режим: отвечай на языке запроса, не уходи в лишние шутки, не размазывай мысль. Для фактчекинга это полезно, потому что каждый лишний слой творчества увеличивает шанс на ошибку. Я бы даже сказал, что чем короче рамка, тем чище результат — особенно если задача типовая и повторяется каждый день.
Не придумывай факты
Ключевая фраза тут — не представлять догадки как факт. Вот это ядро. Если данных нет, модель должна прямо писать, что не может подтвердить утверждение. На практике это снижает количество липовых цифр, выдуманных дат и псевдоцитат. У клиента было так: менеджеры брали сгенерированный ответ, а потом удивлялись, почему в тексте есть цифра, которой в исходнике вообще не было. После жесткого правила про недоказанные факты таких сюрпризов стало заметно меньше.
Источники и цитаты
Блок про источники очень важен, но его часто читают формально. А зря. Если вы просите указывать автора, название, дату и ссылку или идентификатор, вы не просто делаете ответ аккуратным, вы заставляете модель работать как помощника-архивариуса. Ну и тут же отваливается половина красивых, но пустых фраз. Когда источник нельзя назвать точно, ответ становится слабее, зато честнее.
Формат ответа
Структура с ролью, TL;DR, ответом, источниками и статусом проверки полезна потому, что она дисциплинирует и модель, и человека. На моей практике именно формат спасает в длинных задачах: когда у тебя десять фактов, три спорных тезиса и один конфликтный источник, проще проверять блоками, чем читать сплошной текст. Вот тут промт превращается из просьбы в рабочий регламент.
Где такой промт ломается
Самая частая проблема — промт не лечит отсутствие данных. Если источников нет, ИИ не должен фантазировать, и это правильно. Но если вы ждете от него полноценный аналитический ответ по теме, где свежесть данных критична, а доступа к вебу нет, то получите либо отказ, либо слишком осторожную формулировку. Недавно сталкивался с этим на разборе отраслевой статистики: модель честно писала, что не может подтвердить часть цифр, и это было лучше, чем уверенный вымысел, но как итог ответ оказался слишком пустым для публикации.
Вторая боль — чрезмерная строгость. Если промт заставляет модель помечать весь ответ как Unverified при малейшем сомнении, вы теряете полезную градацию. Там, где можно было бы разделить подтвержденное и спорное, система уходит в один общий отказ. Ил это проблема промта, или вашей постановки задачи, решать приходится вам. Поэтому я бы не делал режим проверки слишком дубовым: нужен баланс между честностью и практической пользой.
Как использовать в SMM и контенте
В SMM такой промт экономит нервы на модерации контента. Когда у команды из 8 человек, как было у одного нашего клиента в Краснодаре, появляется привычка проверять каждый тезис через один и тот же шаблон, скорость падает не сильно, а брак — падает заметно. Бюджет там был 120к в месяц, и любая ошибка в цифре вылезала дороже, чем час ручной проверки. А в контенте это вообще больное место: один неверный тезис в посте, и потом уже никто не помнит, кто его туда поставил.
Я тут пробовал связать фактчек с визуальным потоком, и это работает лучше, чем кажется. Для карточек с выводами удобно использовать AI-удаление фона, если нужен чистый фон под цитату или цифру, а генератор анимированных баннеров помогает быстро сделать пометку вроде «проверено» или «источник внутри». Если вы потом адаптируете тот же тезис под соцсети, пригодится AI-генератор подписей для соцсетей — он выдает несколько вариантов подачи, и можно выбрать самый сухой, без лишнего пафоса.
Для отчетов и источников хорошо работает сокращатель ссылок с аналитикой — видно, кто реально открывал материалы и по каким ссылкам ходили чаще. А если у вас презентация, PDF или чек-лист для команды, положите туда генератор QR-кодов, и любой сотрудник быстро дойдет до первоисточника без ручного поиска. Ну, мелочь, а экономит кучу времени и лишних вопросов.
Что я бы добавил в промт
Если взять исходный шаблон как есть, он слишком жесткий. Я бы оставил главную идею — не выдумывать факты и всегда отмечать непроверенное — но смягчил бы то, что заставляет модель ломаться на мелочах. В реальной работе важнее не идеальная формула, а предсказуемый результат: сначала подтвержденное, потом спорное, потом вывод. Вот это и дает нормальный рабочий режим.
Первое улучшение — попросить ИИ отдельно показывать, что подтверждено, что требует проверки и чего не хватает. Второе — добавить приоритет источников: первоисточник, официальный документ, свежая публикация, и только потом пересказ. Третье — разрешить один короткий уточняющий вопрос, если тема расплывчатая. На моей практике это часто спасает от длинного, но бесполезного ответа. Четвертое — попросить модель указывать уровень уверенности простыми словами, без псевдонаучных выкрутасов.
Еще я бы убрал из промта избыточную строгость про спецсимволы и ждал бы не только проверки, но и короткого объяснения, почему факт нельзя подтвердить. Когда модель пишет просто 'I cannot verify this.', это полезно, но не всегда достаточно. Если же она объясняет, что не хватает даты, автора или исходного документа, вы получаете не отказ, а список дыр. А это уже нормальная база для редактора, который не хочет копаться в тексте полдня.
Практический сценарий на 15 минут
Помню как-то запускали внутренний поток для контент-команды, и там было важно не столько генерировать текст, сколько быстро отсеивать мусор. Рабочая схема оказалась простой: сначала задаем тему, потом подкладываем исходники, затем просим ИИ проверить факты, и только после этого отдаем материал редактору. Без этого шага человек начинает верить красивой подаче, а не источнику. А это уже тупик.
Я бы делал так. Сначала формулируете один вопрос, без каши из пяти подтем. Потом прикладываете все, что есть под рукой — документы, ссылки, цитаты, скриншоты, выписки. Затем просите модель вернуть результат в строгой структуре: что подтверждено, что не подтверждено, что спорно, какие источники использованы. После этого вручную проверяете только узкие места. В большинстве случаев это быстрее, чем читать весь текст с нуля.
Если задача регулярная, сохраните промт как шаблон и не трогайте его каждую неделю. Короче, стабильность здесь важнее творчества. Когда у вас один и тот же формат проверки, команда быстрее учится, а ошибки становятся предсказуемыми и заметными. А предсказуемая ошибка — это уже почти управляемый процесс.
Часто задаваемые вопросы
Можно ли заставить ИИ всегда говорить правду?
Что делать, если ответ помечен как Unverified?
Нужен ли браузинг для фактчекинга?
Как и��пользовать такой промт в SMM?
Почему ИИ все равно ошибается после промта?
Если коротко, промт для фактчекинга нужен не для красоты, а для дисциплины. Он заставляет ИИ отделять подтвержденное от предположений и экономит время там, где раньше команда спорила с текстом, а не с фактами.
Но это не волшебная кнопка. Рабочий результат появляется только тогда, когда у вас есть источники, понятная структура и человек, который финально смотрит на ответ. Вот тогда ИИ становится нормальным помощником, а не уверенным фантазером.